タダで手に入る画像生成AI「Stable Diffusion」が凄いらしい
画像生成AI「Stable Diffusion」が世界を変えるくらい凄いらしい。画像生成AIは今まで様々なものがあったが、社会への影響が大きすぎると一般への公開が限定的だった。しかしStability AIは開発した高性能画像生成AI「Stable Diffusion」を無料でソースコードまで公開してしまった。しかも「Stable Diffusion」で生成した画像はフリーで商業利用可だ。
Stability AIはなんでそんな太っ腹を通り越したことをやってくれるのかと言うと、「10億人の人々をクリエイティブにしたかった」からだとStability AIの創業者であるエマード・モスタークは語っている。今後は音声や動画、3DのAIも公開していく予定らしい。楽しみだね!
実質タダで高品質な画像が何でも手に入るとなったらデザインや広告、クリエイティブなどの業界は一晩にして変わるだろう。いちいちイラストレーターに画像を依頼して何日か待って出来上がってきた画像に指示をしてなんてトロいことしなくても、AIに何回か指示して生成された画像を使えばいいんだから。個性や芸術性が必要ないプレゼンのイメージ画像なんかは全部AIに任せればいい(でもいらすとやはしぶとく残りそう……)。インディーズでゲーム作ったり個人で漫画描いている人にとっては喉から手が出るほど欲しかったアシスタントだ。
AIを動かす環境もgoogle colab使えばタダやぞ
とは言っても動かすための環境が必要で、作動させるためにはは10GB以上のビデオメモリとNVIDIA製GPUを搭載したビデオカードが必要らしい。
じゃあ自分のパソコンじゃ駄目だと思っていたら、googleが提供している機械学習の教育・研究用環境「Google Colaboratory(colab)」を使えばgoogleの提供しているGPUを使えるから低スペックPCでもブラウザ上でStable Diffusionを動かせるとインターネットで見た。
Stability AIはAIが一部の大企業に囲い込まれるのは良くないからStable Diffusionを公開したのに、大企業の提供するサービスでAIを動かすのは筋違いじゃねえのか? と思わなくもないが、ありがたくgoogle colabを利用させて貰うことにした。弱者は使えるものは何でも使っていかなきゃいけねぇんだ……!
しかし今後個人でのAI使用が普及していったらそのための高性能PCやゲーミングパソコンの需要が爆発的に高まるだろうし、今のうちに関係する株を買っておいたほうがいいかもしれない。
google colabを使ってStable Diffusionを動かしたら10分でできた
google colabでどうStable Diffusionを動かすのかは以下のページを見てやったのでそちらを見てもらうのが早い。終わるまで10分もかからなかった。
画像生成AI「Stable Diffusion」を低スペックPCでも無料かつ待ち時間なしで使う方法まとめ
上のページには書かれてないけど、下記の指示で画像サイズを変えることもできる。何故かサイズは512か768しか受け付けてくれないけど……。あんまり大きいのは無料で使わせてくれるGPUの性能を超えるからだろうけど、サイズが小さくても駄目なのはよくわからない。当たり前だけどサイズによって生成時間は長くなって、横幅が1.5倍になるだけで時間は30秒から1分くらいに伸びる。
prompt = "指示"
image = pipe(prompt, height=512, width=768)["sample"][0]
image.save(f"sample.png")
一度接続が途切れたら最初からコードを動かし直す必要がある。同じことをやってるはずなのになぜか動かなかったら、とりあえず更新してもう一度最初からやってみてほしい。
しかしタダの環境ではGPUを利用できる時間に限りがあり、一日分使い果たすとまた12時間のクールタイムが必要になる。欲しい絵を生成させるためには試行錯誤がかなり必要なのでこれは残念。あー無制限に動かせる自分のゲーミングパソコンが欲しい。月1000円くらいgoogle colabに課金しようかしら。どのくらい使える量が増えるのかわからないけど……。
グラボ高すぎ
Stable Diffusionで生成した絵
以下はためしにStable Diffusionで生成した絵である。微妙にサイズ違ったり端っこに白い線が入ってるのは、いちいち保存してられないほど作ったので、簡易的にGyazo1)超簡単にスクリーンショットが取れてWEBに保存できるアプリってscrapboxに貼っておいたからなので気にしないでいただきたい。

パソコンの前に座っている男性をレンブラントが描いた油絵

ローポリの警察官

雪の中の美女

時に侵食された大伽藍
*
命令として長い文章を並べるのもどんな絵ができるかワクワクできる。
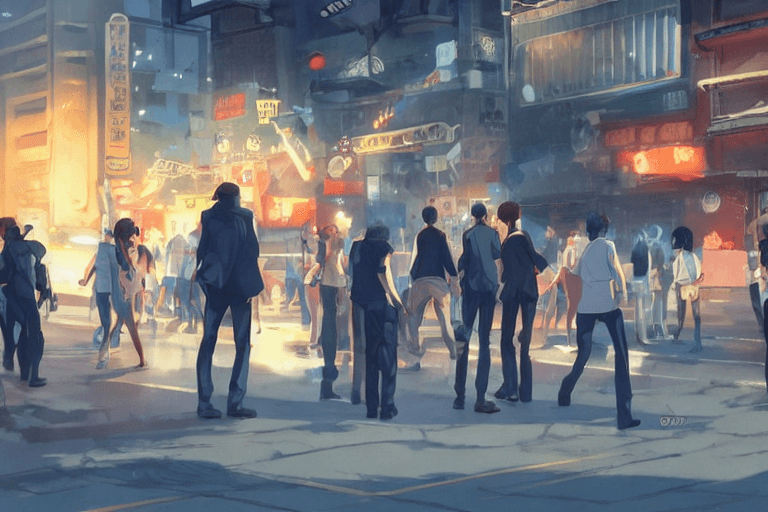
平沢進のBigBrotherの歌詞「路上、スタンガンの 電撃が打つ群衆の影 ヤイヤイと人は行き 秘密裏に事は成る」の英詩をAIに食わせた時の絵。
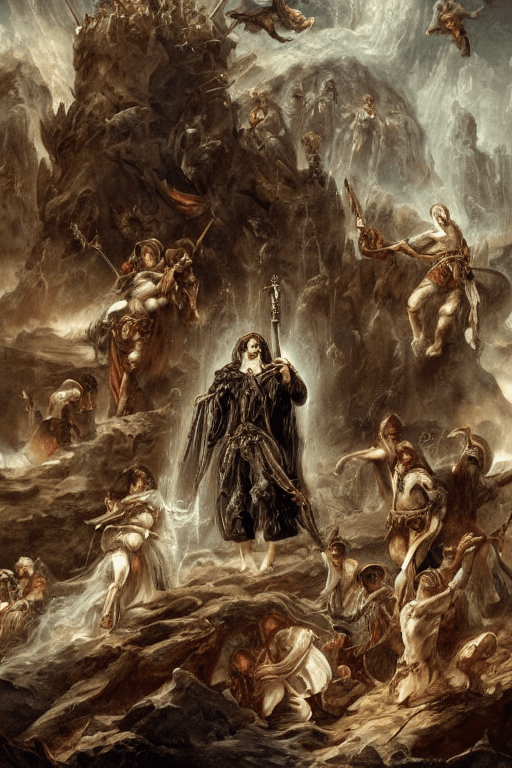
ジョン・ダンの説教「誰がために弔いの鐘は鳴るのか それは汝のためである」の一節を食わせた時の絵。
生成した画像に裸の女体があったりするとNSFW(職場の閲覧には適さない)という表示が出て黒い画像が出るのだけど、「クリムト風で」と頼むとかなりの確率でNSFWが出る。ウィーン大学大講堂の天井画が「これエッチすぎでは?」と大議論を呼んだ約130年後、AIにも「これエッチすぎでは?」と言われるとはクリムトも思っていないだろう。


上の2枚はStable Diffusionくんに何度も何度も繰り返させて基準をかいくぐった「中華服を着た綾波レイ」。なかなかそれっぽいのではないでしょうか。
*
多分、全部AIにやらせるよりAIの生成したものをフォトショで組み合わせるとか、自分で一部書き足すとかコラージュして使うのが当分の間は便利だと思う。

こういうパロディ絵だったら自分でサクっと描いたほうが早いし(コラしたほうがもっと早いのは言うまでもないけど)。
Stable Diffusion以後の世界はどうなるのか?
AIができてもイラストレーターや漫画家は残るだろう
デジタルで絵を描けるようになってもアナログで絵を描く行為がなくならなかったのと同じように、AIができたからといってイラストレーターや漫画家が職を失うってことはないと思う。AIに方向性を与える人間は最低限いるし、手で描いたほうが早いものも多い。どこかで見たアレを作るのはAIは得意だが、魅力的でオリジナルな「画風」を作るのは多分難しい。ストーリーに添ってコマ割りとなるとなおさらだ。
人間は物語を食って生きていくものだから才気走った個人のイラストレーターや漫画家をカリスマと崇め、その作成物に高額の値段をつけることをやめたりはしないだろう。
AIが普及すると逆にライブペインティングみたいにアナログで絵を描く行為の価値がもっと上がるかもしれない。今でも大量生産された雑誌や単行本で見ることが前提のはずの漫画というメディアの『原画展』なんてものが人気なくらい「ブツ」としての絵には価値があるが、その価値がもっと釣り上がるイメージで。歌手がライブで歌うように絵描きがライブで絵を描くことがもっとイベントとして盛り上がったり。
AI以後のクリエイターに求められる能力
CGで絵作りするのが当たり前になってグリーンバックに囲まれて演技する俳優に想像力が要求されるようになったように、これからの絵描きやイラストレーターが必要になってくるのはAIに指示する表現力と監督力だろう。
AIに上手く上奏する能力がいる
AIは指示通り描いてくれるといっても非常に気が回らない存在であり、人間の言語処理とは全然違う言葉の取り方をする。だから狙った通りの絵を生成させるためにはコツがいる。これはグーグル検索で欲しい情報を引っ張ってくる能力と似ている。
” “(二重引用符)で囲った単語は完全一致で検索することを知っているか? マイナス検索は知っているか? site:コマンドでサイト内検索ができることは? こうした検索テクニックみたいなものが画像生成AIへの命令の仕方にもある。
ベーシックな方式として、『【全体のイメージ】【具体的に書かせたいもの】【有名な画家の名前】【味付け】をいくつか』という構成にするとコントロールがしやすい。
*
【全体的なイメージ】を決める単語、例えば古い写真の「old black and white photograph」とか、水彩画「watercolor painting」などで最初に方向性を決める。

第一次世界大戦で戦った戦闘蒸気象の古い写真
【画家の名前】は、ゴッホ風「painted by Gogh」とか、ミュシャ風に「by Alfons Maria Mucha」とか、北斎風に「by Hokusai」などを命令することで画風を決めてくれる。アニメ風の画風が欲しいなら新海誠風に「by Makoto Shinkai」が強い。スタジオジブリ風に「in Studio Ghibli style」もいいね。
AIならではの命令として画家に共作させるというのもできる。
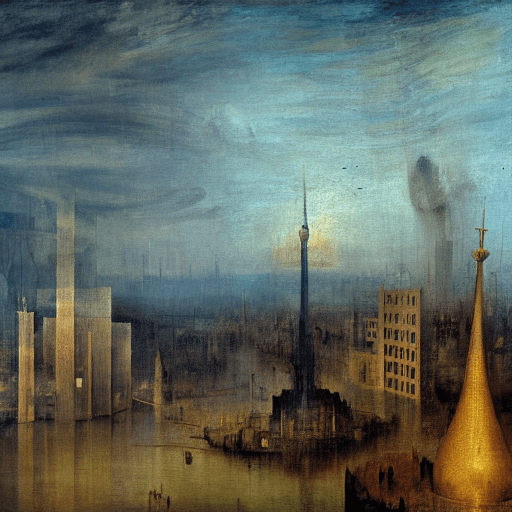
ヒエロニムス・ボスとJ. M. W. ターナーに描かせた摩天楼

アンリ・マティスとアンリ・ルソーに描かせた摩天楼(名前で考えた)
【味付け】は柔らかな光で「soft lighting」、とにかく細かく「highly detailed」、アンリアルエンジン(ゲームの制作エンジン)で作ったみたいに綺麗に「unreal engine」とか。「高級カメラの名前」「シャッタースピード」は被写界深度をコントロールできる。カメラ用語も勉強しなきゃ駄目だな……。
ちなみに上に貼った大伽藍の絵は「by XT IQ4 150MP 32mm」とか「8k」とか「cinematic lighting」とか「divine atmosphere」とか【味付け】をかなり盛っている。

「variant comic cover」でアメコミの昔の表紙っぽくなる。
そしてこのようにAIへ上手く指示して望む結果を引き出すことを「プロンプトエンジニアリング」というのだそうだ。神に祝詞を上奏する神官がいたように、現代ではAIに命令を伝える仕事が職業になり得るのである。
より監督的資質が求められるが、ある意味チャンスでもある
そしてAIによって手を動かして絵を描く時間が減った分が注がれるのは、作品のテーマへあらゆる細部が奉仕しているかという全体の完成性、逆にこれまでにない突き抜けた前衛性などではないだろうか? つまり職人というよりAIという技術者を用いて作品を完成させる監督としての側面がこれからのクリエイターは強まっていくと予想する。もちろんこれまでのクリエイターの中でも優れたクリエイターはやっていたことだが。
ただ技術修練の時間を魅力的な作品の構築に使えるようになると考えると、Stability AIの「10億人の人々をクリエイティブにしたかった」という願いは叶っていくのではないか。
だから自分はAIをガンガン使って使い倒したい。自分の望む絵をこの世に顕現させられるならデジタルでもAIでも使いたい。
AIは人間を労働から解放してくれるか(多分してくれないだろうなぁ)
Stable Diffusionは絵を描くことのうち相当のことを助けてくれるし、AIはこれからどんどんいろんな分野で使われるようになるだろうが、じゃあそれで人類が労働から解放されるかと言ったら多分ないと思う。理由は下の画像を見て貰えればわかる。

車輪が発明されて以後の世界では車輪を前提にした労働量になったし、蒸気機関が発明されて以後は蒸気機関を前提にした労働量になったし、コンピューターが発明されて以後もコンピューター前提の労働量になった。AIもAI補助前提の仕事量になるだけだろう。
ケインズは「2030年には人々の労働時間は週15時間になる。 21世紀最大の課題は余暇だ」と予測したそうだが、後8年で2)2030年が後8年後だということに気が遠くなりかけた労働時間が週15時間になるだろうか? AIもどうせ人間から労働を奪ってなんてくれないよ。
個人的にはAIのこれからを非常に楽しみにしてます

いずれにしろすでに賽は投げられた。これから生まれてくる技術に人間は適応するしかないし、また適応できるだろう。個人的には今後映像や音楽、3Dの世界にまで広がるAIの力が非常に楽しみだ。3DのAIとStable Diffusionを組み合わせたら絵のカメラアングルやパースを自由自在に設定できそうだし、このAIで描いた絵を音楽化してさらにその音楽を絵画化したりする伝言ゲームやったらどうなるかとかも面白そう。
特に3D自動生成AIに非ッ常に興味があるんですよ……。漫画の背景描きたくねえという欲求に答えてくれそうでね……。Stable Diffusionは同じキャラのポーズ変えたのとか同じ風景のカメラアングルの変更とかがほとんど無理なので。

![]()